
前の章では非常に簡潔なAIチャットアプリを作成しました。この章では、Streamlitの様々な機能を勉強しながら、もう少し作り込んでみましょう。
前の章と同じく、まずは動作概要図(前章と同じです)、完成したアプリが動いているGIF画像および完成版のコードを置いておきます。
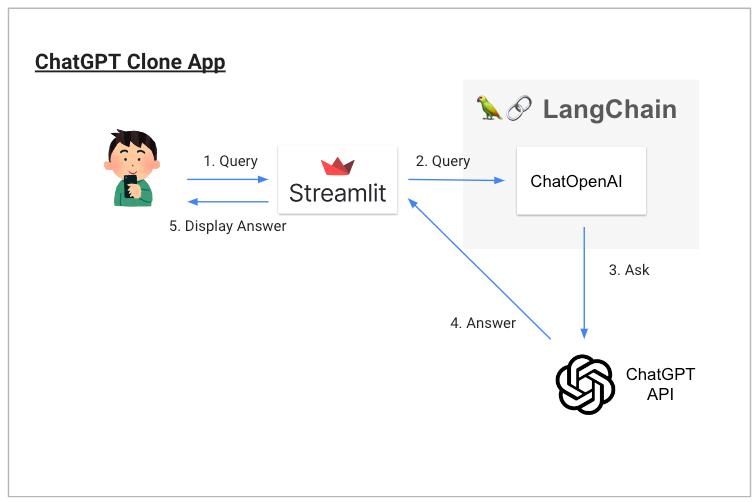
注意: この章のコードは2025年8月現在の最新仕様に合わせて更新されています。OpenAI APIの価格体系やStreamlitの新機能など、多くの変更が反映されています。
完成版コード
(完成版のコードは章末に掲載します)
この章で学ぶこと
- Streamlitでサイドバー付きの画面を作る方法を知る
- Streamlitの色々なウィジェットを知る (sliderやradio)
- tiktokenを使ったトークン数の計算方法を学ぶ
- 最新のOpenAI APIの直接使用方法を学ぶ
- 2025年現在の効率的なStreaming表示の実装方法を学ぶ
色々なオプションの使い方を学ぼう
サイドバーに色々表示してみよう
さて、AIチャットアプリにサイドバーを設置して、色々なオプションを選択可能にしてみましょう。サイドバーの設置は非常に簡単です。
以下のように st.sidebar から書き始めれば、サイドバーに要素を設置することができます。以下のコードは要素の設置だけなので、これだけではまだ動きません。
# サイドバーのタイトルを表示
st.sidebar.title("Options")
# サイドバーにオプションボタンを設置
# 2025年8月現在の主要モデルに更新
model = st.sidebar.radio("Choose a model:", ("GPT-4.1", "GPT-4.1-mini"))
# サイドバーにボタンを設置
clear_button = st.sidebar.button("Clear Conversation", key="clear")
# サイドバーにスライダーを追加し、temperatureを0から2までの範囲で選択可能にする
# 初期値は0.0、刻み幅は0.1とする
temperature = st.sidebar.slider("Temperature:", min_value=0.0, max_value=2.0, value=0.0, step=0.1)
# Streamlitはmarkdownを書けばいい感じにHTMLで表示してくれます
# (もちろんメイン画面でも使えます)
st.sidebar.markdown("## Token Usage")
st.sidebar.markdown("**Total Tokens**")
for i in range(3):
st.sidebar.markdown(f"- Query {i+1}: {(i+1)*150} tokens") # 説明のためのダミー
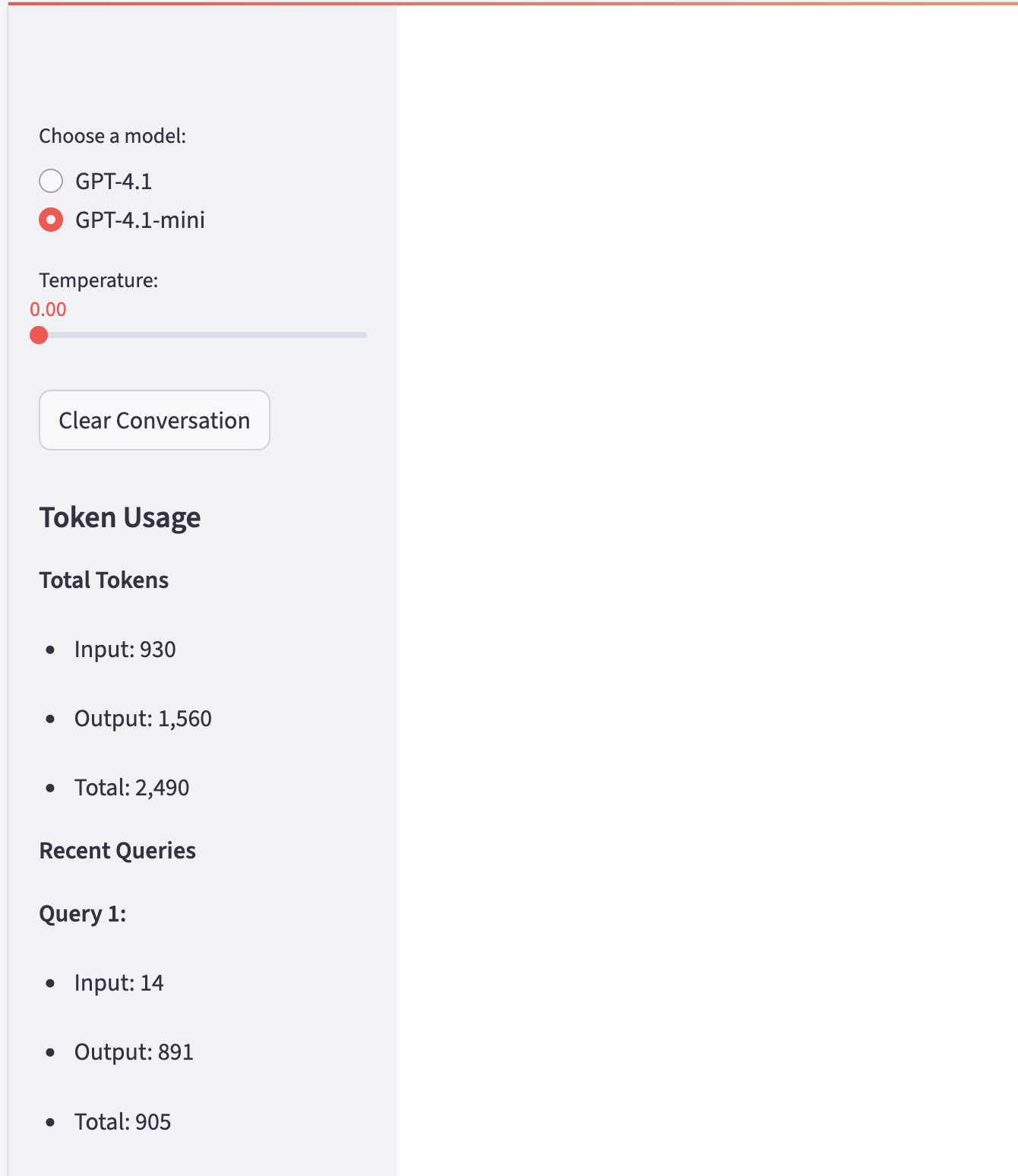
2025年の補足: - モデル選択肢を最新のGPT-4.1系に更新しました - コスト表示からトークン数表示に変更(より確実な計測が可能) - GPT-4.1は従来のGPT-4oと比較して26%安価になっています
オプションボタンを利用しよう
サイドバーに要素が設置できたら、それを利用するコードを書いていきましょう。
以下のコードではオプションボタンを押すたびにmodelの値が変化します。その変化に応じて、OpenAI APIのmodelパラメータに代入される文字列が変わり、その結果として利用するモデルを変更することができます。
# 2025年版:OpenAI APIを直接使用
from openai import OpenAI
def get_openai_client():
"""OpenAIクライアントを初期化"""
return OpenAI()
def select_model():
model = st.sidebar.radio("Choose a model:", ("GPT-4.1", "GPT-4.1-mini"))
if model == "GPT-4.1":
model_name = "gpt-4.1" # 2025年現在の正しいモデル名
else:
model_name = "gpt-4.1-mini" # 2025年現在の正しいモデル名
# モデル名を返す
return model_name
重要な変更点(2025年版): - 大幅簡素化: LangChainを削除し、OpenAI APIを直接使用 - よりシンプル: 余計な抽象化レイヤーを排除 - 直接的: OpenAI APIの機能をストレートに活用
余談ですが、gpt-4に「あなたはなんのモデル?GPT4?」と聞いても「私はGPT-3をベースとしたAIです。GPT-4はまだ存在していません。」と回答することがあります。デバッグの際などは気を付けてください。(僕はこのせいで小一時間程度無駄なデバッグ作業を行う羽目になりました)
2025年版補足: GPT-4.1系では、このような誤った回答はほとんどなくなりましたが、それでも以下の方法で確実にモデルを判別できます。
なんのモデルを使っているかは、後述のトークン数計算の結果を確認するとすぐにわかります。数百から数千トークンを使っているならGPT-4系を使っていることが多いでしょう。
2025年版のトークン数目安: - GPT-4.1: 高精度だが、1回のやりとりで100-500トークン程度 - GPT-4.1-mini: 効率的で、同じやりとりで50-300トークン程度 - 数十回のやりとりで数千〜数万トークンが目安
また、「大谷翔平選手が外野から160km/hの球を投げる。この時、ホームベースまで何秒で到達する?」といった、少し捻った問題を出すことでもすぐに判別可能です。GPT-3.5は外野から
という文字列をほぼ100%見落として、間違った回答を返してきます。
2025年版補足: GPT-4.1系では文脈理解能力が大幅に向上しており、このような細かい条件も正確に読み取れるようになっています。
スライダーを利用しよう
オプションボタンの利用とほぼ同じです。以下のようなコードになります。
def select_model():
model = st.sidebar.radio("Choose a model:", ("GPT-4.1", "GPT-4.1-mini"))
if model == "GPT-4.1":
model_name = "gpt-4.1"
else:
model_name = "gpt-4.1-mini"
# サイドバーにスライダーを追加し、temperatureを0から2までの範囲で選択可能にする
# 初期値は0.0、刻み幅は0.01とする(原文では0.1だったが、より細かい調整が可能)
temperature = st.sidebar.slider("Temperature:", min_value=0.0, max_value=2.0, value=0.0, step=0.01)
return model_name, temperature
2025年版の詳細補足:
- step=0.01により、より細かいtemperature調整が可能
- GPT-4.1系では、temperatureの違いによる出力の変化がより予測しやすくなっています
- temperature=0.0でも完全に決定論的ではない場合があるため、再現性が必要な場合はseedパラメータの使用も検討してください
履歴を消してみよう
同様に、クリアボタンも利用可能にしてみましょう。
これは以下のような init_messages 関数とし、main 関数から呼び出して使うと良いでしょう。クリアボタンを押したときに、メッセージ履歴初期化と同じ処理を走らせると、履歴を消すという処理が実現できます。
def init_messages():
clear_button = st.sidebar.button("Clear Conversation", key="clear")
if clear_button or "messages" not in st.session_state:
st.session_state.messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
# 2025年版:トークン履歴も管理
st.session_state.tokens = []
def main():
init_page()
model_name, temperature = select_model() # モデル名と温度を取得
init_messages()
# ・・・
2025年版の重要な変更点:
- シンプルな辞書形式: LangChainのメッセージクラスから標準的な辞書形式に変更
- セッション状態の管理がより安定化されました
- st.session_state.tokensでトークン履歴も同時にクリアできるようになっています
詳細補足: Streamlitのセッション状態は、ブラウザのタブを閉じるかページをリロードするまで保持されます。クリアボタンを押すことで、会話履歴とトークン履歴の両方を一度にリセットできるため、新しい話題で会話を始めたい時に便利です。
便利な機能を学ぼう
tiktokenを使ったトークン数の計算
OpenAI APIを使用する際、トークン数を正確に把握することは非常に重要です。トークン数が分かれば、実際のコストも計算できますし、API制限の管理もしやすくなります。
2025年現在、最も確実にトークン数を計算する方法は、OpenAI公式のtiktokenライブラリを使用することです。以下のように実装できます。
import tiktoken
def get_token_count(messages, model_name, response_text=""):
"""手動でトークン数を計算"""
try:
# モデルに応じたエンコーダーを取得
if "gpt-4" in model_name.lower():
encoding = tiktoken.encoding_for_model("gpt-4")
else:
encoding = tiktoken.get_encoding("cl100k_base")
# メッセージをテキストに変換
full_text = ""
for msg in messages:
if isinstance(msg, dict) and 'content' in msg:
full_text += msg['content'] + "\n"
input_tokens = len(encoding.encode(full_text))
output_tokens = len(encoding.encode(response_text)) if response_text else 0
return input_tokens, output_tokens, input_tokens + output_tokens
except Exception as e:
st.sidebar.error(f"Token count error: {e}")
return 0, 0, 0
2025年版の重要なポイント:
- tiktoken.encoding_for_model()を使用してモデル固有のエンコーダーを取得
- GPT-4系ではgpt-4のエンコーダーを使用
- 辞書形式のメッセージに対応(LangChain依存を削除)
- エラーハンドリングを含め、安定した動作を保証
以下に、サンプルのコードとその結果を表示します。
# 使用例
input_tokens, output_tokens, total_tokens = get_token_count(
st.session_state.messages, model_name, response_text
)
print(f"Input Tokens: {input_tokens}")
print(f"Output Tokens: {output_tokens}")
print(f"Total Tokens: {total_tokens}")
# 2025年版の出力例:
# Input Tokens: 25
# Output Tokens: 42
# Total Tokens: 67
トークン数を表示しよう
計算したトークン数をサイドバーに表示する機能も実装してみましょう。
def display_tokens():
tokens = st.session_state.get('tokens', [])
st.sidebar.markdown("## Token Usage")
if tokens:
# 合計トークン数を計算
total_prompt_tokens = sum(token_info['prompt_tokens'] for token_info in tokens)
total_completion_tokens = sum(token_info['completion_tokens'] for token_info in tokens)
total_tokens = sum(token_info['total_tokens'] for token_info in tokens)
st.sidebar.markdown("**Total Tokens**")
st.sidebar.markdown(f"- Input: {total_prompt_tokens:,}")
st.sidebar.markdown(f"- Output: {total_completion_tokens:,}")
st.sidebar.markdown(f"- Total: {total_tokens:,}")
# 最新の3件のみ表示
if len(tokens) > 1:
st.sidebar.markdown("**Recent Queries**")
recent_tokens = tokens[-3:] if len(tokens) > 3 else tokens
for i, token_info in enumerate(recent_tokens):
query_num = len(tokens) - len(recent_tokens) + i + 1
st.sidebar.markdown(f"**Query {query_num}:**")
st.sidebar.markdown(f" - Input: {token_info['prompt_tokens']:,}")
st.sidebar.markdown(f" - Output: {token_info['completion_tokens']:,}")
st.sidebar.markdown(f" - Total: {token_info['total_tokens']:,}")
else:
st.sidebar.markdown("**Total Tokens**")
st.sidebar.markdown("- Input: 0")
st.sidebar.markdown("- Output: 0")
st.sidebar.markdown("- Total: 0")
Streaming表示も可能
2025年現在、Streamlitでは st.write_stream という非常にスマートな機能が利用できます。これにより、従来よりもはるかに簡単にStreaming表示を実装できます。
# 過去の履歴は普通に表示する
messages = st.session_state.get('messages', [])
for message in messages[1:]: # システムメッセージ以外を表示
if message["role"] == "assistant":
with st.chat_message('assistant'):
st.markdown(message["content"])
elif message["role"] == "user":
with st.chat_message('user'):
st.markdown(message["content"])
# 最新のやりとりをストリーミング表示
if user_input := st.chat_input("聞きたいことを入力してね!"):
st.session_state.messages.append({"role": "user", "content": user_input})
with st.chat_message("user"):
st.markdown(user_input)
with st.chat_message("assistant"):
# 2025年版:OpenAI APIの直接ストリーミング
client = get_openai_client()
stream = client.chat.completions.create(
model=model_name,
messages=st.session_state.messages,
temperature=temperature,
stream=True
)
response = st.write_stream(stream)
# 手動でトークン数を計算
input_tokens, output_tokens, total_tokens = get_token_count(
st.session_state.messages, model_name, response
)
# トークン情報を保存
token_info = {
'prompt_tokens': input_tokens,
'completion_tokens': output_tokens,
'total_tokens': total_tokens
}
st.session_state.tokens.append(token_info)
st.session_state.messages.append({"role": "assistant", "content": response})
2025年版の大きな改善点:
- LangChain削除: OpenAI APIを直接使用し、よりシンプルに
- st.write_stream()により、非常にスムーズなStreaming表示が可能
- トークン数計算とStreaming表示を同時に実行可能
- 実装がシンプルになり、エラーが起こりにくい
- ChatGPTライクな自然な表示が実現可能
完成版コード(2025年8月最新版)
以下が実際に動作する完成版のコードです:
import streamlit as st
from openai import OpenAI
import tiktoken
def init_page():
st.set_page_config(page_title="AI Chat App", page_icon="🤖")
st.header("🤖 AI Chat App")
def get_openai_client():
"""OpenAIクライアントを初期化"""
return OpenAI()
def select_model():
model = st.sidebar.radio("Choose a model:", ("GPT-4.1", "GPT-4.1-mini"))
if model == "GPT-4.1":
model_name = "gpt-4.1"
else:
model_name = "gpt-4.1-mini"
temperature = st.sidebar.slider("Temperature:", min_value=0.0, max_value=2.0, value=0.0, step=0.01)
return model_name, temperature
def get_token_count(messages, model_name, response_text=""):
"""手動でトークン数を計算"""
try:
# モデルに応じたエンコーダーを取得
if "gpt-4" in model_name.lower():
encoding = tiktoken.encoding_for_model("gpt-4")
else:
encoding = tiktoken.get_encoding("cl100k_base")
# メッセージをテキストに変換
full_text = ""
for msg in messages:
if isinstance(msg, dict) and 'content' in msg:
full_text += msg['content'] + "\n"
input_tokens = len(encoding.encode(full_text))
output_tokens = len(encoding.encode(response_text)) if response_text else 0
return input_tokens, output_tokens, input_tokens + output_tokens
except Exception as e:
st.sidebar.error(f"Token count error: {e}")
return 0, 0, 0
def init_messages():
clear_button = st.sidebar.button("Clear Conversation", key="clear")
if clear_button or "messages" not in st.session_state:
st.session_state.messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
st.session_state.tokens = []
def display_tokens():
tokens = st.session_state.get('tokens', [])
st.sidebar.markdown("## Token Usage")
if tokens:
# 合計トークン数を計算
total_prompt_tokens = sum(token_info['prompt_tokens'] for token_info in tokens)
total_completion_tokens = sum(token_info['completion_tokens'] for token_info in tokens)
total_tokens = sum(token_info['total_tokens'] for token_info in tokens)
st.sidebar.markdown("**Total Tokens**")
st.sidebar.markdown(f"- Input: {total_prompt_tokens:,}")
st.sidebar.markdown(f"- Output: {total_completion_tokens:,}")
st.sidebar.markdown(f"- Total: {total_tokens:,}")
# 最新の3件のみ表示(重複を避けるため)
if len(tokens) > 1:
st.sidebar.markdown("**Recent Queries**")
recent_tokens = tokens[-3:] if len(tokens) > 3 else tokens
for i, token_info in enumerate(recent_tokens):
query_num = len(tokens) - len(recent_tokens) + i + 1
st.sidebar.markdown(f"**Query {query_num}:**")
st.sidebar.markdown(f" - Input: {token_info['prompt_tokens']:,}")
st.sidebar.markdown(f" - Output: {token_info['completion_tokens']:,}")
st.sidebar.markdown(f" - Total: {token_info['total_tokens']:,}")
else:
st.sidebar.markdown("**Total Tokens**")
st.sidebar.markdown("- Input: 0")
st.sidebar.markdown("- Output: 0")
st.sidebar.markdown("- Total: 0")
def main():
init_page()
model_name, temperature = select_model()
init_messages()
display_tokens()
# チャット履歴を表示
messages = st.session_state.get('messages', [])
for message in messages[1:]: # システムメッセージ以外を表示
if message["role"] == "assistant":
with st.chat_message('assistant'):
st.markdown(message["content"])
elif message["role"] == "user":
with st.chat_message('user'):
st.markdown(message["content"])
# ユーザー入力
if user_input := st.chat_input("聞きたいことを入力してね!"):
st.session_state.messages.append({"role": "user", "content": user_input})
with st.chat_message("user"):
st.markdown(user_input)
with st.chat_message("assistant"):
# OpenAI APIの直接ストリーミング
client = get_openai_client()
stream = client.chat.completions.create(
model=model_name,
messages=st.session_state.messages,
temperature=temperature,
stream=True
)
response = st.write_stream(stream)
# 手動でトークン数を計算
input_tokens, output_tokens, total_tokens = get_token_count(
st.session_state.messages, model_name, response
)
# トークン情報を保存
token_info = {
'prompt_tokens': input_tokens,
'completion_tokens': output_tokens,
'total_tokens': total_tokens
}
st.session_state.tokens.append(token_info)
st.session_state.messages.append({"role": "assistant", "content": response})
st.rerun()
if __name__ == "__main__":
main()
完成!
ここまでで、AIチャットアプリが完成しました。冒頭のGIF画像のようにうまく動作しましたでしょうか?
2025年版での主な改善点:
- LangChain完全削除: OpenAI APIを直接使用し、シンプルで分かりやすいコードに
- 最新のGPT-4.1系モデルを使用し、高性能かつコスト効率的
- st.write_stream()による滑らかなStreaming表示
- tiktokenによるリアルタイムトークン数トラッキング機能
- より安定したセッション状態管理
- 依存関係の大幅削減(openai、tiktoken、streamlitのみ)
次の章では、ローカル環境で開発したAIチャットアプリをWEBにデプロイする方法について学びます。